I.
Researchers at the university of Twente recently conducted an experiment involving two different robotic personalities. One, called “Cynthia,” was programmed to have a low, monotonous voice and act seriously, with minimal empathetic actions. Another, dubbed “Olivia” was programmed to have a higher and more expressive voice that varied in pitch more, to tell jokes, and to react in a more empathetic manner (including sighs and expressions of concern) to participants’ conversation attempts.

The researchers found that Olivia was judged to have a more appealing voice, a more pleasant personality, a more overall aesthetic appeal, and better social skills (P<.05). Participants also judged Olivia to have robustly more appealing behavior (p<.001), and to be more like themselves than Cynthia.
The humorous robots were not judged to be significantly more trustworthy, however, which disconfirmed previous results. Additionally, about half of the feedback about the humor was positive and half was negative, which seems to indicate that adding humor to a robot won’t necessarily endear it to everyone. The researchers mention that a larger sample size might help to confirm the issue; the sample size was only 28 people, which is pretty common for robotics studies.
Interestingly, the robot’s level of empathy did not have a statistically significant impact on any metric – robot likability, robot trustworthiness, robot social skills, the subject’s overall enjoyment, etc – despite the fact that “empathetic robot” behavior seemed significantly different than non-empathetic behavior. Consider the example transcript below supplied by the researchers to demonstrate the differences between the two types of robots.

The researchers also dip into gender differences in reaction to the robots. They found that male participants seemed to like Olivia’s high-pitched voice more than women, but also found Cynthia’s appearance and content presentation slightly more positive than women did. Women seemed to respond better to the robot’s humor than men did. Lastly, men responded more positively to the empathetic robot on one sub scale question, while women responded more positively to the non-empathetic robot on two different subscale questions.
(For the record, I am personally unsure about ALL these results, because most of them rely on P<.05 values on a bunch of subscale questions, and presumably some number of those subscale questions will be under that threshold simply by chance.)
Importantly, there was one group of users who responded significantly better to introverted Cynthia than anyone else. That group was introverts, who found interactions with Cynthia easier (p=.012) and her behavior more empathetic (P<.001) than extroverts. This made me curious, because most of the results seem to demonstrate that extroverted Olivia got overwhelmingly more positive responses from users than introverted Cynthia, which heavily implied that making robots more empathetic and expressive was an unequivocal good. Are there any users for whom that might not be true?
II.
Fortunately, other studies have examined this directly. This study from USC about socially assistive robots (robots who help with social rather than physical tasks) found that introverted users seem to respond more positively to introverted robots, and that extroverted users responded more positively to extroverted robots.
Introverted robots’ voices were quieter and had lower pitch, and were programmed to stick to a “nurturing” script. They uttered phrases like “I’m glad you’re working so well,” “Please continue just like this,” and “I hope it’s not too hard.” Extroverted robots’s voices were louder, faster, and more expressive, and their script was more aggressive. They uttered phrases like “Move! Move!” And “You can do more than that!”
When introverted robots were matched with introverted subjects, they spent about 40% more time interacting with the robots.

But some undetermined number of the participants also completed all the tasks. If enough users finished the tasks, then it’s possible longer time on task actually signifies less efficient task completion. Without exact numbers for which proportion of participants completed all the tasks, we can’t be sure.
The researchers also report tested several different accents and genders, but don’t report significant results. Οverall, these results seem to support the idea of personality-matching for socially assistive tasks, but there are reasons to be unsure, including a small sample size (19 participants).
III.
Another study from USC looks at the benefits and drawbacks of human-robot personality matching via adorable robot-dog AIBO [link]. These researchers point out that some theories posit that opposing personalities (eg, introvert subjects paired with extrovert robots) might produce a more enjoyable experience than similar personalities. The researchers point out that previous work with “embodied software agents,” which I’m pretty sure means robots with bodies – did indeed find that opposing personalities get better results.

A particularly adorable (recent) pic of AIBO.
This kind of makes sense, especially because the researchers highlight the dominant/submissive personality access. I’m not surprised that a dominant person might prefer a compliant robot who didn’t challenge them very often, or that a submissive person might prefer a robot who was good at making decisions. But I feel like this theory is more believable when examining the dominant/submissive personality axis than among the introvert/extrovert axis, although this study (with over 300 citations) seems to make a pretty convincing case that this might be true when it comes to bosses and workplace productivity. Extroverted bosses can exhort passive employees towards better performance, but are “less receptive to proactivity” from employees than their introverted counterparts.
In order to design a more introverted AIBO, the researchers made AIBO’s lights less colorful and less active. They also programmed its movement to be slower and more constrained than the extrovert AIBO, as well as less frequent. Introvert AIBO’s vocalizations and voice were also programmed to be more quiet and more monotonous.
On a scale of 1-10, extrovert AIBO was judged to be about, on average, about a 7, while introvert AIBO earned an average of a little less than 6. The standard deviation was nearly 1.5 points, however, indicating that the ratings varied highly between participants.
When participants were matched up with robots with opposing personalities, the participants judged AIBO to be significantly more socially attractive and more intelligent than when the personalities were similar. Additionally, the interactions seemed to be more enjoyable, although the p-value did not reach the significance threshold of (p<.05).
These two studies aren’t necessarily contradictory. It’s possible that people like playing with pet-style robots whose personalities are different from their own, but prefer matching personalities when working with socially assistive robots on tasks. The robots seem to be accomplishing different goals, and it wouldn’t surprise me if users judged pet robots with opposing personalities to be more intelligent and socially attractive because the difference between the robot’s personality and their own made it seem more interesting and life-like. It also wouldn’t be surprising if robots with similar personalities were preferred during tasks, where cognitive differences might seem less interesting and more frustrating.
I hate to conclude with the dreaded “more research needs to be done” paragraph, but I’m not quite sure what to make of these results. I think the Olivia/Cynthia experiment helps to demonstrate that people tend to prefer more extroverted robots on the whole, but I’m not sure that extroversion and introversion is what that experiment was testing. Olivia seemed more anthropomorphized in general than Cynthia, and her reactions seemed slightly more complex (e.g, adding sympathetic sighs). I wonder how much of the preference for Olivia simply reflects that human are more interested in robots that appear to have more detailed capabilities. The AIBO experiment and the socially assistive experiment offer contradictory results, but they also study different things and use different metrics (self-reported satisfaction vs. time on task).
My takeaway is that we not only need more personality research in HRI than we have right now, but we need an understanding that personality research on HRI in certain circumstances does not necessarily generalize to all circumstances.


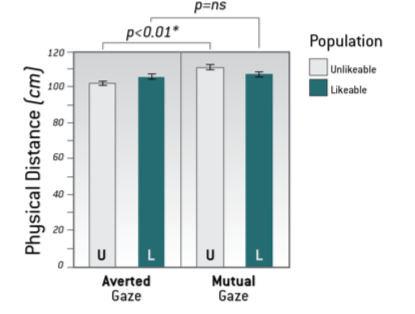 We see that people faced with an unlikeable robot staring at them maintained significantly more distance from the robot (staying on average 111 centimeters away) compared to people faced with an unlikeable robot who averted its gaze (who stayed about 102 centimeters away).
We see that people faced with an unlikeable robot staring at them maintained significantly more distance from the robot (staying on average 111 centimeters away) compared to people faced with an unlikeable robot who averted its gaze (who stayed about 102 centimeters away). When the robot gazes directly at the participant, men but not women give the robot a wider berth (113 centimeters away vs 103 centimeters away).
When the robot gazes directly at the participant, men but not women give the robot a wider berth (113 centimeters away vs 103 centimeters away).